Add Content
Glassix AI Chatbot thrives on information. The more you provide, the better it performs. This AI chatbot can utilize external support content, such as your website, files (PDF and Word), snippets, and Q&A pairs. You can choose the specific sources of information you want the AI Chatbot to use when responding to customers' questions.
AI Chatbot will automatically generate answers based on the support content you add, and you'll have the opportunity to preview these responses before they go live.
As your support content improves, so do the resolution rates and performance of the Glassix AI Chatbot.
Start adding your support content here.
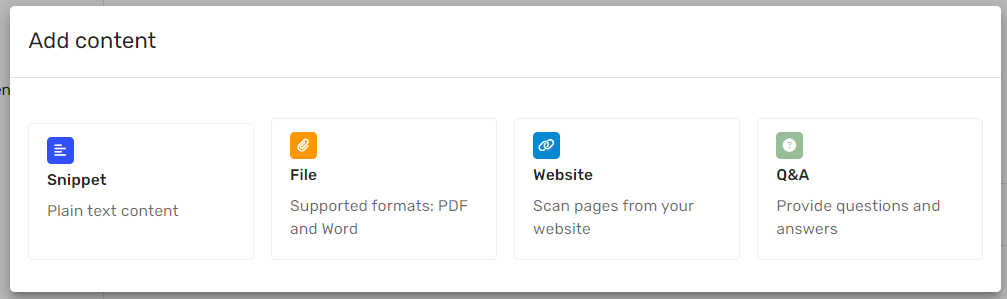
Website
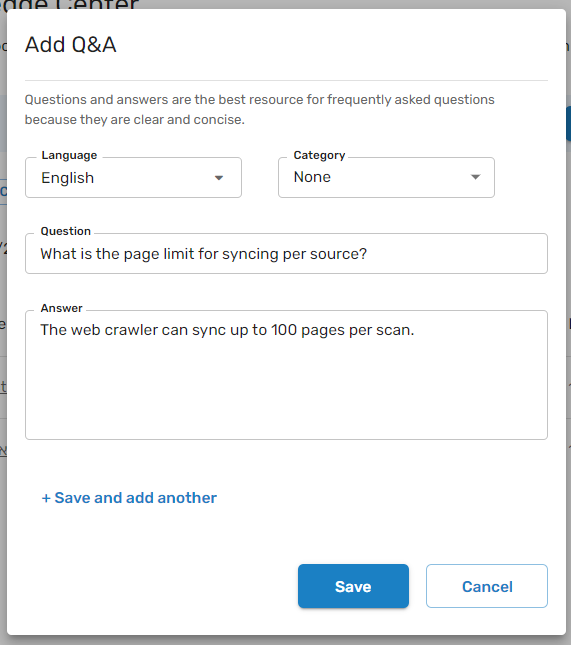
Q&A
Q&A is an essential content type; it is accurate and concise, making it an ideal data source for the AI Chatbot to rely on for its answers. If you have a question that your customers ask repeatedly, add this question and answer as a Q&A. If the 80/20 rule applies to what your customers ask, a small number of questions is responsible for 80% of the overall volume of the questions. Add the frequently asked questions as Q&A content.
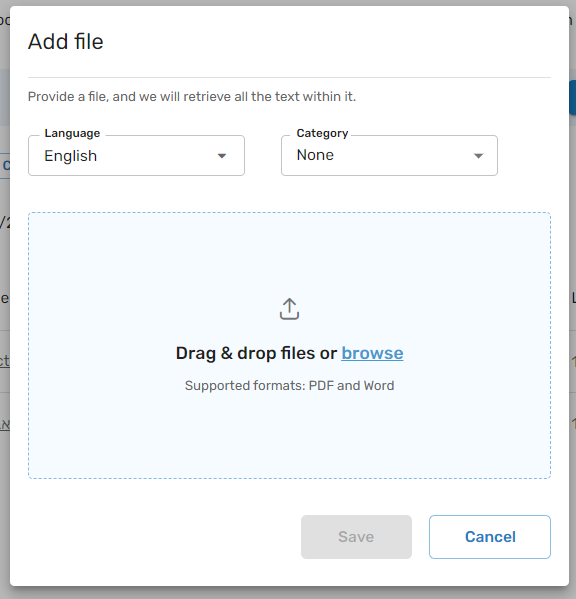
Files
PDF and Word files are another content source that Glassix AI Chatbot can consume. Upload a PDF/Word file, and the text content and images containing text will be scraped and made available for the AI Chatbot to use within minutes.
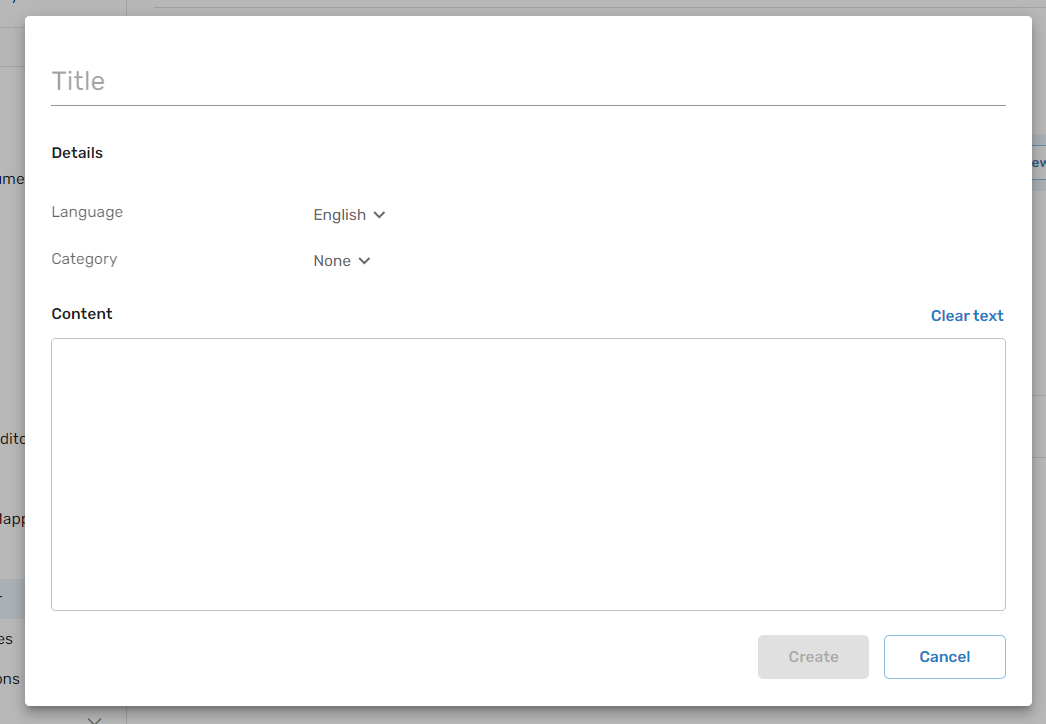
Snippets
Snippet is a simple, plain text - it comes in handy when you want to add new content like:
- Canned replies: Using existing conversation canned replies.
- Private knowledgebase: Information from knowledge bases that are not publicly accessible and cannot be imported into Glassix via the website crawler or as a file.
- Bug/Issue Details: Specific bug or issue information that should not be searchable in your public knowledge base. Although not relevant to all customers, this information would be beneficial for the AI Chatbot in addressing specific customer inquiries.
For optimal results, we suggest breaking longer content, such as an FAQ list, into multiple snippets instead of uploading it as one long snippet. This approach helps the AI Chatbot learn and search through your content more efficiently.
Removing Access to Content
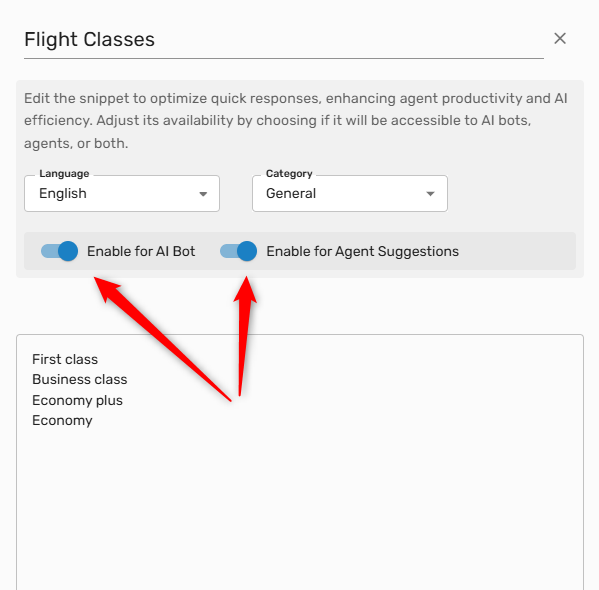
You may adjust access to any of your content for both Agent Suggestions and AI Bots in order to improve the accuracy or specificity of the information provided by each.
Tip:Access to content in the conversation history category is only available for Agent Suggestions. You may still remove access from Agent Suggestions to any of the content in the conversation history if, for example, you would like to remove outdated or inaccurate responses provided in the past by your agents.
In order to adjust access to a specific piece of content in the Knowledge Center, simply select the content item and switch access on or off using the provided switches:
Updated 7 months ago