Scan a Website
Extract text content from any public URL (pages on your website, pricing, blog posts, etc.)
📖 Overview
📍 The web crawler will scan only web pages from your domain. Links to content on other domains or documents/PDFs will be ignored.
📄 We recommend using a URL dedicated to an FAQ, knowledgebase or help center, where the content primarily focuses on answering customer questions. Including irrelevant content may decrease the AI Chatbot's success rate.
⏲️ The scan process can take up to 15 minutes, depending on the amount and type of the website.
Getting there
You can access "scan a website" via Content management page
Or: Go to Settings → AI Chatbot → Knowledge Center → Click Add new → Website
🚀 Quick start
There are 3 ways to scan a website
Scan a single URL page
Scan a URL and it's sub-links (recursively)
Scan an entire website by its sitemap
What is a Sitemap?
A sitemap is a file that lists all the website’s pages to help search engines scan the site better, we currently support only /sitemap.xml path. For example: example.com/sitemap.xml.
1. Fire a scan: Scan max 100 pages from a website (multi page scan)
Enter a URL, select "Website", Click "Save".
Screenshot - minimal settings to extract max 100 pages
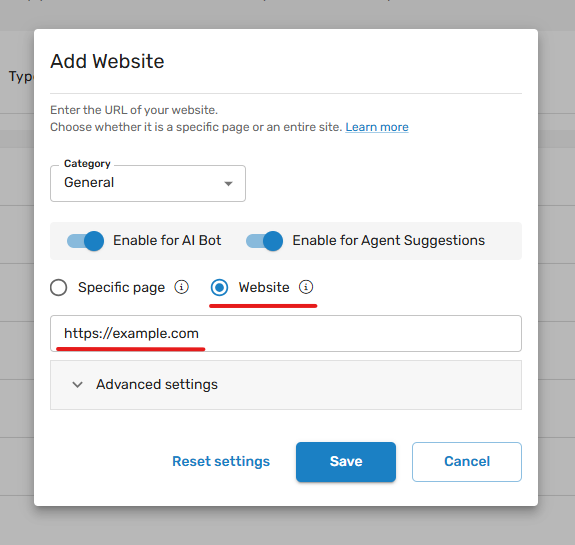
Your scan is now in progress - it will might take a few minutes. A result notification will appear on screen after processing - succuss or failed result of the scan. If the scan failed or the pages scanned do not contain some critical content of the page - we will try again by tweaking some of the advanced settings.
2. The scan failed or the extracted content was insufficient?
Here's some rules of thumb to extract pinpoint results 👍
Here's some helpful rules of thumb - these will help you extract the best results possible:
✅ If crawl has failed and "Proxy type" is "Datacenter" - the scan was most likely was blocked. Switch it to "Residential". Info about proxy type
✅ If a webpage has some loading state or you are aware the page is rendered dynamically by Javascript - use Crawler type: Dynamic
✅ If the extract content is missing some crucial text that does exists on the page - turn the HTML transformer OFF
Scan settings
Scan mode
Screenshot - Crawl type
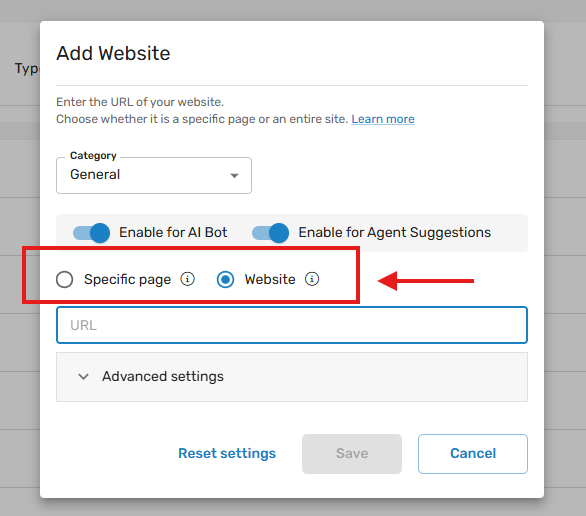
- Specific page: scan a single page. example: enter the URL - https://docs.glassix.com/docs/bot-best-practices, we’ll scan only that particular page.
- Website:: Scan the URL and links found on that pages and the next ones. The number of pages scanned is controlled by max results and max depth properties or by sitemap.
General Advanced settings
Crawler type
- Static: if your webpage is based on classic HTML, CSS, JS combo.
- Dynamic If there is a visible page loading or your website is based on SPA (single page application - such as React, Angular, Vue)
👍 Rule of thumb: is there any loading visible in the webpage? - use "Dynamic".
Proxy type
- Datacenter: we will scan your website from these 3 IP's:
107.175.80.80, 162.212.175.22, 107.172.69.119. This way - you can whitelist these IP's to ensure a successful scan of your website. - Residential: the scan will be initiated using residential IP addresses in your current country.
👍 Rule of thumb: If a scan failed using "Datacenter" switch to Residential. This will bypass blocking mechanisms of websites.
CSS selectors to click on
Use this setting to specify which elements on the page the crawler should interact with. For example, elements like buttons, links, or dropdowns can be targeted. You can define selectors using attributes like aria-expanded="false" to target collapsible sections, class*="question", class*="FAQ", class*="accordion", and similar patterns.
CSS selectors to ignore
This setting allows you to exclude specific elements from the crawl, such as navigation bars, footers, and scripts.
Text to Ignore
Text snippets that will be removed from the extracted results.
HTML Transformer
When active - the scan will extract what seems to be only the relevant text content, by removing small unmeaningful text.
👍 If content appears on the webpage but is missing from the scan, turn off the HTML transformer.
Multi page advanced settings
Max crawl depth
This setting controls how deep the crawler should go within your site’s link structure. For example: if set to 5 - the crawler will follow links up to 5 levels deep.
Max pages
This setting limits the number of pages the crawler will scan. Max 3000 pages.
Use sitemap
Enable this option if you want the crawler to prioritize scanning URLs listed in your website's sitemap.
URL globs to include
Specify patterns or globs to include in the crawl. For example, you can use /products/** to ensure that only product pages or a specific section of your website are crawled. This helps focus the crawl on relevant parts of the site.
URL globs to ignore
You can define globs here to exclude certain URLs from the crawl, such as specific sections or file paths that don’t need to be scanned. For instance, if /products/** or certain directories should be skipped, add those here.
🔦 Examples
We will try to match the optimal scan settings for each scenario
Page scenario #1 - simple page with small chunks of text
- No visible loading in the page
- No need to click on elements
- Page contains many small chunks of texts
Suggested scan settings:
-
Crawler type: Static.
Reason: no visible loading and no need to interact with the page - like clicking elements) -
HTML transformes OFF.
Reason: Small chunks of text might be ignored when HTML transforer is active.
Page scenario #2 - follow sublinks
- No visible loading in the page
- The scan needs to follow 5 links that appear on the page (click on buttons to go to other pages)
Suggested scan settings:
-
Scan mode: Website.
Reason: We need to extract content from sublinks - it's no longer a single page. -
Max crawl depth: 2.
Reason: The page you have entered is depth 1 - the sublinks are depth 2. -
Max pages: 10+ Reason: We need to leave a small "breathing room" - the scan might extracted unwanted links.
FAQ
The scan failed, what to do?
Steps to create a successful scan:
-
Switch Proxy Type
If the current proxy type is set to "Datacenter", change it to "Residential".
Reason: Residential proxies are more likely to bypass a website's blocking mechanisms.
After switching, attempt to rescan. -
Change Crawler Type
If Step 1 fails, adjust the crawler type:
If currently using "Static", switch to "Dynamic"
If currently using "Dynamic", switch to "Static"
Then, attempt to rescan again. -
Remove Clickable Elements (Dynamic Only)
If Step 2 fails while using the "Dynamic" crawler, remove all clickable elements from the crawl configuration.
Once adjusted, try rescanning.
The scan extract extra unwanted text
Inspect the target page - find the element in which the unwanted text is and copy one of the CSS selectors (Id or classname etc). Then you can tweak the scan setting via "CSS selectors to ignore".
The scan is missing content that is on the page
- If the missing text is visible on the page by default (no need to click anything to reveal it) - turn HTML transformer OFF
- If the missing text is is not visible by default - we recommend switch to following settings:
- Crawler type: Dynamic
- Click elements: inspect the clickable elements and enter the CSS selector
Try to rescan.
Can content from password-protected websites be scanned?
No, only content from publicly accessible websites can be synced. Content from a protected site must also be made publicly available to sync.
What is the page limit for scanning a website
You can scan up to 3000 pages
Updated 7 months ago